現有自然語(yǔ)言問(wèn)答的視頻理解研究大多采用離線(xiàn)特征提取方式來(lái)進(jìn)行問(wèn)答推理,然而這種離線(xiàn)的處理方式存在一些缺陷:(1)視頻或文本特征提取器通常是在其他任務(wù)上進(jìn)行訓練的,與目標任務(wù)存在差異,如將行為識別數據集上訓練的特征提取器直接用于視頻問(wèn)答任務(wù)顯然不是最優(yōu)的。(2)各個(gè)特征提取器通常是在各自領(lǐng)域數據集上單獨進(jìn)行訓練,得到的模態(tài)特征之間缺乏聯(lián)系。(3)為提升問(wèn)答推理表現,這類(lèi)方法通常需借助于復雜的特征提取器或文本分析工具以更有效地處理視頻或問(wèn)題。因此,采取端到端的方式來(lái)對自然語(yǔ)言問(wèn)題和視頻內容進(jìn)行學(xué)習是解決上述缺陷的一種有效途徑。盡管近年來(lái)提出的端到端方法通過(guò)同時(shí)學(xué)習特征提取與多模態(tài)信息交互,并在問(wèn)答推理上取得了優(yōu)異的識別表現。然而,這些方法主要關(guān)注于構建參數量龐大的模型以及探索如何利用大規模視覺(jué)文本語(yǔ)料庫的預訓練來(lái)提升任務(wù)性能,而這通常需要耗費大量的計算資源,且在數據標注和模型訓練上具有較高的人力成本。
我院研究團隊針對現有研究方法存在的上述問(wèn)題,提出了一種高效的端到端視頻和語(yǔ)言聯(lián)合學(xué)習方法。該方法結合了現有研究中所驗證的局部空間信息和時(shí)間動(dòng)態(tài)特性對于提升問(wèn)答推理準確性的幫助,通過(guò)設計金字塔式視頻和語(yǔ)言交互結構,將視頻分解成具有不同粒度的空間和時(shí)間特征,并堆疊多個(gè)多模態(tài) Transformer層提取其與問(wèn)題之間的交互,實(shí)現了視頻和文本之間的局部和全局依賴(lài)關(guān)系提取。此外,為更充分地利用各層上的局部和全局交互特征,該方法設計了一種基于上下文匹配的橫向連接操作以及多步損失約束,以逐步地實(shí)現局部和全局語(yǔ)義完整的交互特征的提取。
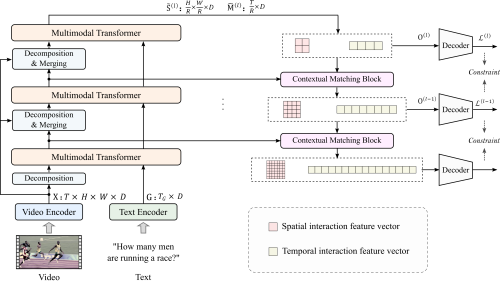
方法框架圖
本研究方法能夠在無(wú)需建立參數量龐大的特征提取以及交互模型,且在不借助于大規模視覺(jué)文本數據對預訓練的情況下,取得與現有方法相比更好或相當的推理表現。同時(shí)在模型參數量和計算效率上具有顯著(zhù)優(yōu)勢。相關(guān)成果發(fā)表在人工智能頂會(huì )議AAAI Conference on Artificial Intelligence(CCF A類(lèi))上。上述工作得到國家自然科學(xué)基金項目的支持。相關(guān)論文鏈接:https://ojs.aaai.org/index.php/AAAI/article/view/25296