????近年來(lái)隨著(zhù)深度攝像機和多攝像頭系統的出現,多視角三維人體姿態(tài)估計逐漸成為三維人體姿態(tài)估計領(lǐng)域的最熱門(mén)研究方向之一。多視角三維人體姿態(tài)估計能夠通過(guò)利用多個(gè)視角的數據,來(lái)補充在遮擋、相機運動(dòng)等復雜情況下缺失的關(guān)節點(diǎn)位置信息,減輕單視角三維人體姿態(tài)估計存在的深度模糊問(wèn)題。但在實(shí)際應用的非限定環(huán)境下,受場(chǎng)景背景、相機拍攝角度、光照、遮擋等復雜因素的影響,不同視角的圖像信息間存在很大的視覺(jué)表征差異,導致跨視角有效特征提取和融合十分具有挑戰性。
重慶研究院研究團隊針對許多現有的多視角三維人體姿態(tài)估計方法存在忽略關(guān)節點(diǎn)多維度隱含信息、依賴(lài)特定場(chǎng)景的相機參數、語(yǔ)義特征挖掘不足等問(wèn)題,研究了基于深度語(yǔ)義圖編碼器和基于漸進(jìn)性時(shí)空融合的多視角三維人體姿態(tài)估計方法。該研究通過(guò)提取描述人體關(guān)節點(diǎn)豐富空間結構信息的語(yǔ)義圖嵌入特征,構建實(shí)現不同特征間動(dòng)態(tài)交互和融合的空間語(yǔ)義圖編碼器以及跨視角時(shí)空特征融合方法,充分挖掘不同視角關(guān)節點(diǎn)隱含的深層語(yǔ)義知識,增強姿態(tài)特征的表征性。
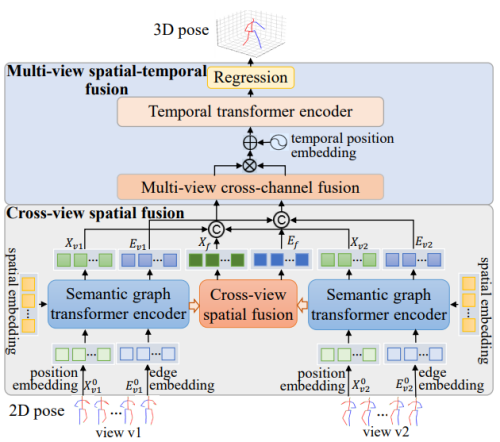
方法框架圖
該研究在不依賴(lài)相機外參的情況下,有效減輕了深度模糊問(wèn)題,提升了三維人體姿態(tài)估計性能。相關(guān)成果發(fā)表在人工智能頂會(huì )AAAI Conference on Artificial Intelligence(CCF A類(lèi))和計算機圖形學(xué)與多媒體頂會(huì )ACM International Conference on Multimedia(CCF A類(lèi))上。
上述工作得到國家自然科學(xué)基金項目的支持。
相關(guān)論文鏈接:
https://ojs.aaai.org/index.php/AAAI/article/view/28549
https://dl.acm.org/doi/abs/10.1145/3581783.3612098